This week brings new functionality to a commonly used part of the Pinata platform: our pin by hash functionality
.
I wanted to take some time to explain this new functionality and dive into the IPFS mechanics surrounding this update.
Come on baby,Without further ado, let’s dive in.
IPFS pinning — How it works
There are two main ways to pin content on an IPFS node:
- Adding a local file to an IPFS node: Adding a local file is how content first becomes part of the IPFS network and is what happens when you upload a file to pin using our pinFileToIPFS endpoint. Essentially, we receive your file via our API and then send it directly to our nodes to be pinned.
- Retrieving content by its hash (Content-Identifier) and pinning it: IPFS also allows you to pin content that exists on the IPFS network but doesn’t reside locally on your machine. This is what happens when you utilize our addHashToPinQueue or pinHashToIPFS endpoints and is the use case we’ll be focusing on in this article.
Pinning by Hash — A deeper look
A quick reminder: When a file is added to an IPFS node, the node returns a Content-Identifier (CID) for the file. The CID that is returned from the IPFS node is the direct result of running the file through a cryptographic hash function. Because of this, the CID is commonly referred to as the content’s “hash” and is how we’ll be referring to the CID for the rest of this article.
The DHT
When a node is connected to the IPFS network, the content that node has is frequently broadcasted over the IPFS Distributed Hash Table (DHT). This means the node is telling all the other nodes that it has certain content. This makes it so that if anybody asks those nodes for that content, they’ll know which node to point the requesting node towards.

MultiAddresses
A key concept to understand here is that when a node “searches for content” by using the DHT, it’s really searching for who has that content. The requesting node uses the DHT to find out which nodes have the content it’s looking for and where those nodes are located at. If the requesting node is able to find a node with the content it’s looking for, the IPFS network will eventually provide back the “multiaddress” of that node hosting the desired content. The multiaddress looks something like this:
/ip4/123.456.78.90/tcp/4001/ipfs/QmAbCdEfGhIjKlMnOpQrStUvWxYzAbCdEfGhIjKlMnOpQr
Multiaddresses can vary in format, hence the “multi” part of “multiaddress”, but the important thing to note is that the multiaddress provides the requesting node with a few things:
- Which protocols to use to communicate with the node
- The IP location of the node
- Which port the node can be reached at
- The unique Peer ID of the node
We’ll talk more about how to find your node’s multiaddress in a bit. But, for now, let’s talk about why this address is important.
Content Retrieval
As mentioned above, requesting nodes use the DHT to find the multiaddress of peers that host content they’re looking for. Once they’ve found this multiaddress, the requesting node directly connects to the host node via IPFS’s “swarm” functionality and starts retrieving the content.
Similarly to how requesting nodes use the DHT to locate content they want to consume, nodes who want to pin content that already exists on the network also use the DHT to locate content they’re looking to pin.
A common issue with this is that it can often take awhile to find which node is hosting the content.
There are a variety of reasons for this. Two common causes are:
- The hosting node has just recently connected to the IPFS network
- The hosting node is connected to very few other nodes
Both of these problems stem from the fact that there are often quite a few degrees of separation between the node requesting the content and the node hosting that content.
Wouldn’t it be great if we could speed up this process?
Speeding up content discovery
If the owner of a requesting node already knows that content is stored on a specific node, it doesn’t make much sense for that node to traverse the DHT to find out which node has that content.
Luckily, IPFS allows us to manually connect to nodes that we already know about. I talk about this mechanism in a previous post. To give a quick recap: if we know the multiaddress of an IPFS node, we can manually connect to it using IPFS’s “swarm connect” functionality.
So what does this gain us?
With a direct connection, the requesting node has a “fast-lane” for content discovery on the host node. When the requesting node sends out a request for content, instead of having to wait for its peer nodes to find out who is hosting that content, one of those peers will actually be the node hosting the content. This allows for a near instant response time. Once the requesting node finds out that the host node has the content it desires, it will retrieve the content for pinning.

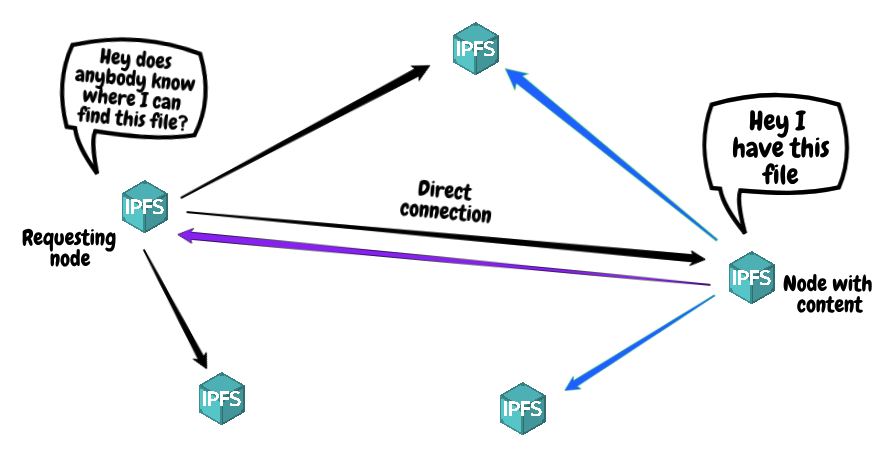
In this scenario we’ve cut out a significant amount of initial time that the requesting node would have otherwise spent searching for the location of the content it desired.
How this was implemented in Pinata
Our new functionality this week can be seen in our addHashToPinQueue or pinHashToIPFS endpoints. Now, when providing a hash to pin, you can provide the multiaddress of up to five nodes that your content already resides on.
If our API notices that you provided host nodes as part of your request, we’ll directly connect to those nodes before attempting to pin your content! This allows us to take advantage of the speed benefits mentioned earlier in this article by cutting out the node discovery process of pinning content.
Finding your multiaddress
To find the multiaddress of a node you’re running simply run:
ipfs id
Your response should look something like this:
{
"ID": "NodeID",
"PublicKey": "NodePublicKey",
"Addresses": [
"/ip4/127.0.0.1/tcp/4001/ipfs/NodeID",
"/ip4/XXX.XXX.XXX.XXX/tcp/4001/ipfs/NodeID",
"/ip6/::1/tcp/4001/ipfs/YourNodeID",
"/ip6/YYYY:YYYY:YYYY:YYYY:YYYY:YYYY:YYYY:YYYY/tcp/4001/ipfs/NodeID",
"/ip6/YYYY:YYYY:YYYY:YYYY:YYYY:YYYY:YYYY:YYYY/tcp/4001/ipfs/NodeID",
"/ip6/YYYY:YYYY:YYYY:YYYY:YYYY:YYYY:YYYY:YYYY/tcp/4001/ipfs/NodeID",
"/ip4/XXX.XXX.XXX.XXX/tcp/4001/ipfs/NodeID",
],
"AgentVersion": "go-ipfs/0.4.17/",
"ProtocolVersion": "ipfs/0.1.0"
}
In the response you should see an “Addresses” array that lists the different multiaddresses for your node. Depending on your network configurations you’ll likely have a few entries listed, but the one you’ll want to take note of is the entry that contains your machine’s “external” IP address. To double check your machines external address, check out this handy tool or run the following in your server’s command line:
dig +short myip.opendns.com @resolver1.opendns.com
How to provide host nodes as part of your request
To provide the multiaddresses of your host nodes as part of your addHashToPinQueue or pinHashToIPFS request, simply add the “host_nodes” property to your request POST body like so:
{
hashToPin: (Your Content's Hash Goes Here),
host_nodes: [
/ip4/host_node_1_external_IP/tcp/4001/ipfs/node_1_peer_id,
/ip4/host_node_2_external_IP/tcp/4001/ipfs/node_2_peer_id,
.
.
.
]
}
And that’s it! By providing the multiaddresses for your host nodes, you can enjoy noticeably faster pinning times for content you’re already hosting. This speed improvement will be especially noticeable for customers attempting to pin content on nodes that have just recently connected to the network or nodes with a low peer connection count.
Conclusion
In situations where it’s already known which nodes are hosting desired content, content retrieval / pinning time can be significantly lowered by having the receiving node make a manual IPFS swam connection to host nodes before pin attempts are made. This removes the need for the receiving node to search for host nodes through the IPFS DHT before retrieving content.